
A case study in accelerating informed decisions
At Illuminate, we provide data engineering expertise to help the analyst access timely, insightful and accurate data and make their job easier. Our data engineering tools are designed to relieve the analyst from having to do painstaking manual data transformation and searches, to focus their analytic skills on the activities that automated tools cannot match such as teamwork, tradecraft, and out-of-the-box thinking. Central to this workflow are the AI models to triage and highlight items of interest which must be continually trained to adapt to new threats and eliminate any biases that could impact accuracy. Accelerating this decision process therefore requires that AI models are deployed and operated at maximum efficiency.
The explosion in use of AI technology has led to optimized hardware to run pre-trained AI models, such as ResNet50 for image classification, against inputs and efficiently create inferred outputs. AI inference can be viewed as a trivially parallel workload that scales with the number of users. The compute intensive nature of AI inference, the inherent parallelism and the scale of the opportunity has led to the development of custom processors such as AWS Inferentia and Google TPU.
Unfortunately scaling AI training is not so straightforward. AI training algorithms use variants of the gradient descent algorithms where the vast number of parameters to be trained in the model receive a series of small adjustments known as gradients, in some relationship to their current contribution to the error in accuracy of the model. Distributed AI training parallelizes this process by running multiple copies of the model as tasks in a cluster and then exchanging gradients between tasks to average the parameter adjustments. HPC facilities offer both accelerated compute and high-performance communications and should therefore be suited to AI training workloads. To investigate this, we leveraged the expertise of our frequent partners at the Edinburgh Parallel Compute Centre (EPCC) and their Cirrus* HPC facility.
Cirrus includes 36 nodes with four Nvidia V100 accelerators each, which are connected via a 54.5Gbps Infiniband fabric. High performance communications libraries support direct transfers between accelerators on the same node and between nodes. This arrangement allowed us to investigate multiple GPU and/or multi-node configurations such as the 2 node / 8 GPU configuration shown below
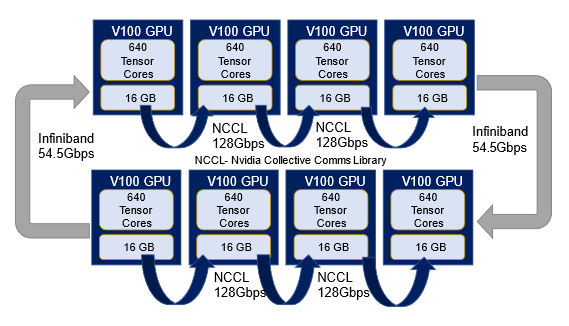
The model we selected for benchmarking was a fully convolutional network for semantic segmentation of images with over 7M parameters coded in TensorFlow. This model was trained using the following three options for parallelizing AI training of TensorFlow models.
- Automatic Mixed Precision (AMP): By representing parameters as a 16-bit value rather than a 32-bit value it is possible to use tensor cores that have double the compute density at reduced precision.
- TensorFlow Distributed Training: TensorFlow provides “strategies” in its distributed training API that can distribute over multiple GPUs (MirroredStrategy) and multiple nodes (MirroredWorkerStrategy).
- Horovod Framework: Horovod uses an approach inspired by HPC and uses the MPI library that is ubiquitous on HPC facilities for communications and task distribution.
The AI training performance of these frameworks was benchmarked as the number of GPUs was increased to investigate the scaling of the system.
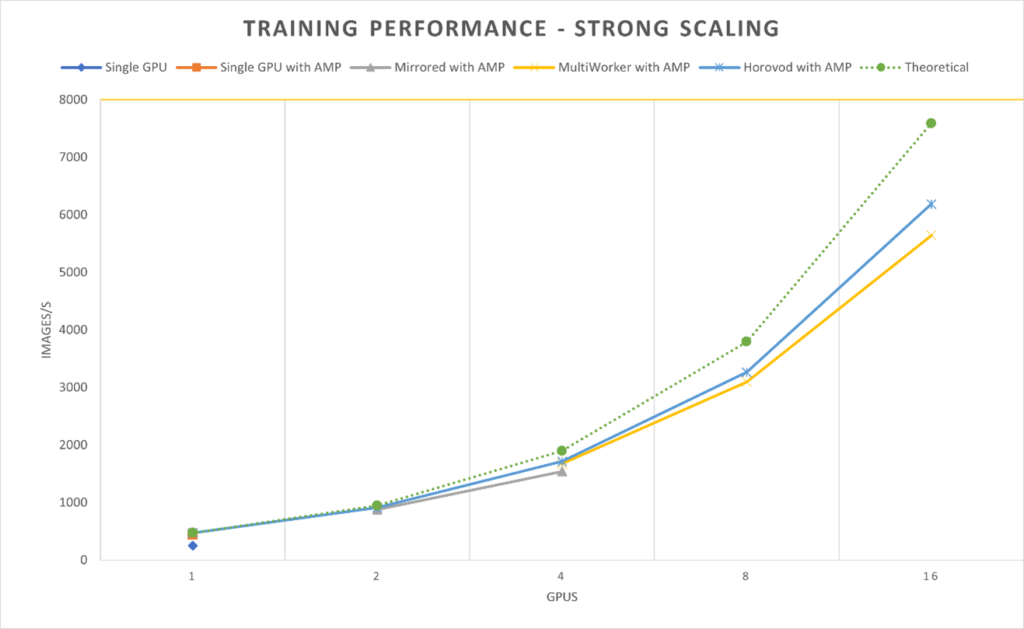
AMP gave a 74% performance boost in the single GPU case so was used in all subsequent benchmarks as the common baseline. The TensorFlow distributed training strategies scaled well but the training code had to be modified twice and elaborate launch scripts were required to pass the cluster configuration to the framework. Horovod achieved 80% efficiency in the 4 node / 16 GPU configuration and offered a 10% boost over distributed TensorFlow. This can be attributed to the use of MPI in Horovod which can use HPC collective communications to exchange gradients as opposed to the point-to-point communications in TensorFlow. Horovod only required the code to be modified once and could be launched with standard MPI command-line parameters. The scalability, simplicity and maintainability of the Horvod-based training approach would make it the preferred option for use in HPC facilities.
Our company’s customer commitment to accelerate informed decisions has many aspects and this study is an illustrative example. Firstly, we accelerated time to result by partnering with a leading HPC facility to use a pre-configured optimized cluster. Secondly, we accelerated efficiency by 90% by leveraging our system engineering expertise to make technology choices and optimize them on Cirrus. Finally, we accelerated the training process 24 times by combining both approaches with minimal adjustments to the source code. These learnings will be applied to ensure that our data pipelines continue to run as efficiently as possible and at peak performance.
* This work used the Cirrus UK National Tier-2 HPC Service at EPCC funded by the University of Edinburgh and EPSRC (EP/P020267/1).


